Bitcoin
数字货币和纸质货币的对比
| 属性 | 分析 | 优势方 |
|---|---|---|
| 便携 | 大部分场景(特别是较大数额支付时)下数字货币将具备更好的便携性 | 数字货币 |
| 防伪 | 两者各有千秋,但数字货币整体上会略胜一筹。 纸币依靠的是各种设计(纸张、油墨 、防伪 暗纹 、 夹层等)上的精巧,数字货币依靠的则是密码学上的保障。 事实上,纸币的伪造时有发生,但数字货币的伪造目前还无法实现 | 数字货币 |
| 辨伪 | 纸币即使依托验钞机等专用设备仍会有误判情况,数字货币依靠密码学易于校验 | 数字货币 |
| 匿名 | 通常情况下,两者都能提供很好的匿名性 。 但都无法防御有意的追踪 | 持平 |
| 交易 | 对纸币来说,谁持有纸币谁就是合法拥有者,交易通过纸币自身的转移即可完成,无法复制 。 对数字货币来说则复杂得多,因为任何数字物品都是可以被复制的,但数字 形式也意味着转移成本会更低 。 总体上看,两者适用不同的情景 | 持平 |
| 资源 | 通常情况下,纸币的生产成本要远低于面额。 数字货币消耗资源的计算则复杂得多 。 以比特币为例,最坏情况下可能需要消耗接近甚至超过面值的电能 | 持平 |
| 发行 | 纸币的发行需要第三方机构的参与,数字货币则通过分布式算法来完成发行。 在人类历史上,通胀和通缩往往是不合理地发行货币造成的,而数字货币尚缺乏大规模验证, 还有待观察 | 持平 |
| 管理 | 纸币发行和回收往往通过统一机构,易于监管和审计;目前出现的数字货币在这方面 还缺乏足够支持和验证 | 纸币 |
双重支付攻击
对于数字货币来说,数字化内容容易被复制。数字货币持有人可以将同一份货币发给多个接收者,这种攻击称为“双重支付攻击”。
数字货币1.0:即银行中通过电子账号里面的数字记录了客户的资产
但他依赖于一个前提:假定存在一个安全可靠的第三方记账机构负责记账,这个机构负责所有的担保环节,最终完成交易。
银行、支付宝都属于这种类型。
去中心化的技术难关
- 货币的防伪:谁负责对货币的真伪进行鉴定
- 货币的交易:如何确保货币从一方安全转移到另外一方
- 避免双重支付:如何避免同一份货币支付给多个接收者
数字货币的定义
数字货币可以认为是一种基于节点网络和数字加密算法的虚拟货币。数字货币的核心特征主要体现在三个方面:
①由于来自于某些开放的算法,数字货币没有发行主体,因此没有任何人或机构能够控制它的发行;
②由于算法解的数量确定,所以数字货币的总量固定,这从根本上消除了虚拟货币滥发导致的可能;
③由于交易过程需要网络中的各个节点的认可,因此数字货币的交易过程足够安全 。
数字货币是一种不受管制的、数字化的货币,通常由开发者发行和管理,被特定虚拟社区的成员所接受和使用。欧洲银行业管理局将虚拟货币定义为:价值的数字化表示,不由央行或当局发行,也不与法币挂钩,但由于被公众所接受,所以可作为支付手段,也可以电子形式转移、存储或交易
比特币的诞生
2008 年 10 月 31 日, 一位化名 Satoshi Nakamoto (中本聪)的人在 metzdowd 密码学邮件列表中提出了比特币( Bitcoin)的设计白皮书《 Bitcoin: A Peer-to-Peer Electronic Cash System 》,并在2009 年公开了最初的实现代码 。
比特币的意义和价值
比特币首次真正从实践意义上实现了安全可靠的去中心化数字货币机制 ,这也是它受到无数金融科技从业者热捧的根本原因 。
- 作为一种概念货币,比特币主要希望解决已有货币系统面临的几个核心问题:
- 被掌控在单一机构手中,容易被攻击
- 自身的价值无法保证,容易出现波动
- 无法匿名化交易,不够隐私
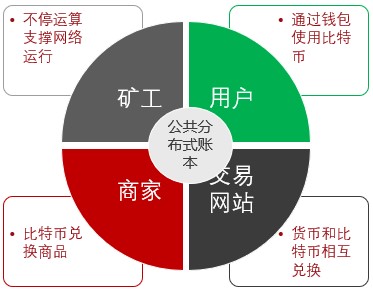
比特币的生态系统如下:
区块链因比特币而生,但是现在已经脱离了比特币网络自身。
Block Chain
区块链本质上是一个去中心化的数据库,又不仅仅是一个数据库。是一串使用密码学方法相关联产生的数据块,每一个数据块中包含了一组比特币网络交易的信息,用于验证其信息的有效性(防伪)和生成下一个区块。
2015年被业界视为区块链元年,2016年则是区块链产业深化发展和全面加速前行的一年,2019年为“上链元年”。
- 区块链的特点
- 分布式容错性:分布式网络及其鲁棒,能够容忍部分节点的异常状态
- 不可篡改性:一致提交后的数据会一直存在,不可销毁和修改
- 隐私保护性:密码学保证了数据隐私,即便数据泄露也无法解析
- 随之带来的业务特性
- 可信任性:区块链技术可以提供天然可信的分布式账本平台,不需要额外的第三方中介机构参与
- 降低成本:跟传统技术相比,区块链技术可能需要时间、人力和维护成本更少
- 增强安全:区块链技术将有利于安全、可靠的审计管理和账目清算,减少犯罪风险
所有跟信息、价值、信用等相关的交换过程,都将可能从区块链技术中得到启发或直接受益。
Wikipedia的定义:是借由密码学串接并保护内容的串连文字记录。类比于一种分布式数据库技术,通过维护数据块的链式结构,可以维持持续增长的、不可篡改的数据记录。
区块链技术最早的应用出现在比特币项目中。
基本概念:
- 交易(transaction):一次对账本的操作,导致账本状态的一次改变,如添加一条转账记录
- 区块(block):记录一段时间内发生的所有交易和状态结果,是对当前账本状态的一次共识
- 链(chain):由区块按照发生顺序串联而成,是整个账本状态变化的日志记录
若把区块链作为一个状态机,则每一次交易是视图改变一次状态,而每次共识生成的区块,就是参与者对于区块中交易导致状态的改变的结果进行确认。
在实现上,首先假设存在一个分布式的数据记录账本,这个账本只允许添加 、 不允许删除 。 账本底层的基本结构是一个线性的链表,这也是其名字“区块链”的来源 。
链表由一个个“区块”串联组成,后继区块记录前导区块的哈希值( pre hash ) 。 新的数据要加入,必须放到一个新的区块中 。 而这个块(以及块里的交易)是否合法,可以通过计算哈希值的方式快速检验出来 。 任意维护节点都可以提议一个新的合法区块,然而必须经过一定的共识机制来对最终选择的区块达成一致。
- 比特币为例,区块链的共组过程
比特币客户端发起一项交易,广播到比特币网络中并等待确认 。
网络中的节点会将一些收到的等待确认的交易记录打包在一起(此外还要包括前一个区块头部的哈希值等信息),组成一个候选区块 。
试图找到一随机串放到区块里,使得候选区块的哈希结果满足一定条件(比如小于某个值) 。 这个 nonce 串的查找需要一定的时间去进行计算尝试。
一旦节点算出来满足条件的 nonce 串,这个区块在格式上就被认为是“合法”了,就可以尝试在网络中将它广播出去 。
其他节点收到候选区块,进行验证,发现确实符合约定条件了,就承认这个区块是一个合法的新区块,并添加到自己维护的区块链上 。
当大部分节点都将区块添加到自己维护的区块链结构上时,该区块被网络接受,区块中所包括的交易也就得到确认 。
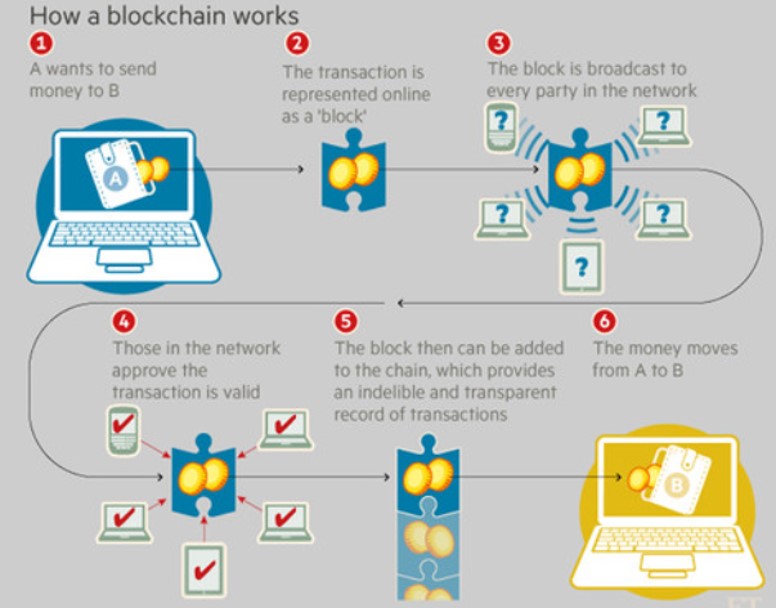
如图,A想要向B发起交易(1,2),做工作量证明,然后将交易广播至区块链网络中(3),让其他节点验证工作量证明(4),验证成功后,将交易区块加入该链的末尾(5),交易成功(6)。
工作量证明
Proof of Work:简称PoW,即工作量证明。比特币的这种基于算力寻找 nonce 串的共识机制。 目前,要让哈希结果满足一定条件,并无已知的快速启发式算法,只能进行尝试性的暴力计算 。 尝试的次数越多(工作量越大),算出来的概率越大 。
通过调节对哈希结果的限制,比特币网络控制平均约 10 分钟产生一个合法区块 。 算出区块的节点将得到区块中所有交易的管理费和协议固定发放的奖励费(目前是 12.5 比特币,每四年减半),这个计算新区块的过程俗称为挖矿 。
比特币网络中存在大量(据估计数千个)的维护节点,而且大部分节点都是正常工作的,默认都只承认所看到的最长的链结构 。 只要网络中不存在超过一半的节点提前勾结一起采取恶意行动,则最长的链将很大概率上成为最终合法的链 。 而且随着时间增加,这个概率会越来越大。 例如,经过 6 个区块生成后,即便有一半的节点联合起来想颠覆被的结果,其概率也仅为(1/2)6 = 1.6% ,即低于 1 /60 的可能性 。当然,如果整个网络中大多数的节点都联合起来作恶,可以导致整个系统无法正常工作 。 要做到这一点,往往意味着付出很大的代价,跟通过作恶得到的收益相比,得不偿失 。
区块链的演化
-
区块链1.0
区块链1.0是随着比特币的发明而引入,基于用于加密货币
-
区块链2.0
主要用于金融服务,在这一阶段引入合同
-
区块链3.0
用于金融服务行业之外,同时还包括政府、卫生、媒体、艺术和司法等更综合的行业
-
Generation X(区块链X)
这是区块链发展过程中一个奇点,有一天我们将会拥有一个公共区块链服务,任何人都可以使用,进而在所有领域提供服务
三种典型演化场景
| 场景 | 功能 | 智能合约 | 一致性 | 权限 | 类型 | 性能 | 编程语言 | 代表 |
|---|---|---|---|---|---|---|---|---|
| 公信的数字货币 | 记账功能 | 不带有或较弱 | Pow | 无 | 公有链 | 较低 | 简单脚本 | 比特币网络 |
| 公信的交易处理 | 智能合约 | 图灵完备 | PoW、PoS | 无 | 公有链 | 受限 | 待定语言 | 以太坊网络 |
| 带权限的分布式账本处理 | 商业处理 | 多种语言、图灵完备 | 包CFT、BFT在内的多种机制、可插拔 | 支持 | 联盟链 | 可扩展 | 高级编程语言 | 超级账本 |
演化出的几种类型:
- 公有区块链:对公众开放,任何人都可以作为节点参与进来。任何人不会持有该账本,而且向任何参与者开放
- 私有区块链:仅向特定组织开放,进而确定账本的共享过程
- 半私有区块链:兼具私有性和公有性,私有部分由某一团体控制,而公有部分则向参与者开放
- 侧链技术:包括单路楔入式侧链和双路楔入式侧链。针对后者,货币可在主链和侧链间移动,并在必要时返回至主链
- 许可账本:参与者是已知且受信的,许可账本不需要使用分布式协商一致机制,相反,可以使用一致性协议来维护共享账本
- 分布式账本:分布式账本分布在参与者之间,并扩散于多个站点或组织中。对应的记录是连续存储的,而不是按情况排序的
- 共享账本:共享的应用程序和数据库
- 全私有和专有账本:适用于组织内部的特定私有环境共享数据,并提供数据的真实性保证
- 标记化区块链:标准的区块链,通过挖掘和初始分布来生成加密货币
- 无代币区块链:不需在节点间传递值,只需在受信各方之间共享数据
区块链是首个自带对账功能的数字记账技术实现
跟传统的记账技术相比,基于区块链的分布式账本应该包括如下特点:
-
维护一条不断增长的链,只可能添加记录,而发生过的记录都不可篡改
-
去中心化,或者说多中心化,无需集中控制而能达成共识,实现上尽量采用分布式
-
通过密码学的机制来确保交易无法被抵赖和破坏,并尽量保护用户信息和记录的隐私性
分类
根据参与者的不同,可以分为公开(public)链、联盟( consortium)链和私有(private)链。
- 公有链,顾名思义,任何人都可以参与使用和维护,如比特币区块链,信息是完全公开的;
如果进一步引入许可机制,可以实现私有链和联盟链两种类型:
-
私有链,由集中管理者进行管理限制,只有内部少数人可以使用,信息不公开;
-
联盟链则介于两者之间,由若干组织一起合作维护一条区块链,该区块链的使用必须是带有权限的限制访问,相关信息会得到保护,如供应链机构或银行联盟 。
分布式系统与去中心化
分布式系统
-
区块链的核心是一个去中心化的分布式系统
-
分布式系统中的节点可以相互交换信息
-
节点分为可信节点、缺陷节点、恶意节点。一个由任意行为的节点被称为拜占庭节点,网络上某个出现任何意外行为的节点都可归类于拜占庭节点。
-
分布式系统的主要挑战:节点与容错的协调,即一个节点的失效不影响整个系统的运行
-
同步系统:Synchronous System: Known bounds on times for message transmission, processing , bounds on local clock drifts, etc.(Can use timeout)
-
异步系统:Asynchronous System: No known bounds on times for message transmission, processing, bounds on local clock drifts, etc.(More realistic, practical, but no timeout.)
CAP定理
cap定理,又称布鲁尔定理:任意分布式系统不能同时拥有一致性、可用性、分区容错性
- 一致性(Consistency):任意节点拥有最新数据副本
- 可用性(Availablitiy):系统在使用期间可以被访问,接收请求并在必要时做出响应
- 分区容错性(Partition Tolerance):一组节点的失效不影响系统的运行
一般是淘宝的系统可用性可以达到5个9,意思是他的可用水平是99.999%,即全年停机时间不超过(1-0.99999)*365*24*60 = 5.256min
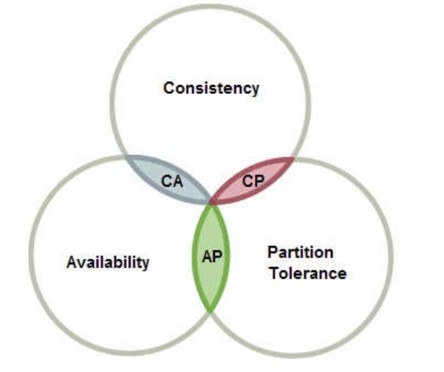
**CP without A **:一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统。分布式存储系统(Redis、Hbase),分布式协调组件Zookeeper.
AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦网络问题发生,节点之间可能会失去联系。为了保证高可用,需要在用户访问时可以马上得到返回,则每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。
淘宝的购物,12306的买票,都是在可用性和一致性之间舍弃了可用性而选择一致性。保证了最终一致性。
然而区块链可以实现这三种属性
通过复制的方式实现容错性
通过一致性算法确保所有节点具有相同的数据
拜占庭将军问题
一群领导拜占庭各部军队的陆军将军,计划从某一城市进攻或撤退。这里,将军们之间的唯一沟通方式是信使,他们需要就同时进攻达成一致意见,以赢得胜利。
**问题:**一名或多名将军或许是叛徒,可以传达一个误导信息。因此,有必要找到一种可行的机制,让将军们之间达成某种协议,这样就可以同时进行攻击。
相较于分布式系统,将军可视作节点,叛国者则视作拜占庭(恶意的)节点,信使是将军之间沟通的渠道。
拜占庭将军失效
所谓拜占庭失效指一方向另一方发送消息,另一方没有收到,或者收到了错误的信息的情形。
在容错的分布式计算中,拜占庭失效可以是分布式系统中算法执行过程中的任意一个错误。这些错误被统称为“崩溃失效”和“发送与遗漏式失效”。当拜占庭失效发生时,系统可能会做出任何不可预料的反应。
这些任意的失效可以粗略地分成以下几类:
进行算法的另一步时失效,即崩溃失效;
无法正确执行算法的一个步骤;
执行了任意一个非算法指定的步骤。
各个步骤由各进程执行,算法就是由这些进程执行的。一个错误的进程是在某个点出现了上述情况的进程。没有出现错误的进程是正确的进程。
拜占庭将军问题——解决算法
拜占庭问题的最初描述是:n 个将军被分隔在不同的地方,忠诚的将军希望通过某种协议达成某个命令的一致(比如一起进攻或者一起后退)。但其中一些背叛的将军会通过发送错误的消息阻挠忠诚的将军达成命令上的一致。Lamport 证明了在将军总数大于3m ,背叛者为m 或者更少时,忠诚的将军可以达成命令上的一致。
- 为了保证上面的需求,必须满足下面两个条件:
- IC1. 所有忠诚的副官遵守相同的命令,即一致性
- IC2. 如果发出命令的将军是忠诚的,那么所有忠诚的副官遵守司令(发出命令的将军)的命令,即正确性
特别提示:
发送命令的每次只有一个将军,将其命令发送给n-1 个副官。
m 代表叛国者的个数,因为将军总数为n,所以副官总数为n-1 个。
IC2 中副官遵守实际上是指忠诚的将军能够正确收到忠诚将军的命令消息。
消息传递
- 通过消息传递达到一致,如果有m 个叛国将军,则将军们的总数必须为3m+1 个以上。下面是消息传递过程中默认的一些条件:
- A1. 每个被发送的消息都能够被正确的投递
- A2. 信息接收者知道是谁发送的消息
- A3. 能够知道缺少的消息
A1 和 A2 假设了两个将军之间通信没有干扰,既不会有背叛者阻碍消息的发送(截断)也不会有背叛者伪造消息的情况(伪造)。即是每个将军都可以无误地将自己的消息发送给其他每个将军。
算法
OM(m)算法:
消息算法OM(m) 。对于所有的非负整数m ,每个发令者通过OM(M) 算法发送命令给n-1 个副官。
# 将军通过副官传递消息:即, 消息传递路线: 将军i--Message-->副官i --boardcast-->副官j--Message-->将军j
(1)发令者将他的命令发送给每个副官。
(2)对于每个i ,vi 是每个副官i 从发令者收到的命令,如果没有收到命令则为撤退命令。副官i 在OM(m-1) 中作为发令者将vi 发送给另外n-2 个副官。
(3)对于每个i,并且j 不等于 i,vj 是副官i 从第(2)步中的副官j 发送过来的命令(使用 OM(m-1)算法),如果没有收到第(2)步中的副官j 的命令则默认为撤退命令。最后副官i 使用majority(v1,…,vn-1)得到命令。
定义majority(cmd1,cmd2,…,cmdn)等于多数派命令。
第一轮将军发给所有副官命令
第二轮n-1副官互通将军发了什么,确定将军是否为叛徒,若将军是叛徒,则将军的消息无效,舍弃;将军忠诚,即可在第二轮已可决定
第三轮n-1副官互通某个副官各给别人发了什么消息,遍历n-2个副官的消息以判断自己作何决定
(例:若L1收到其它L2~L6发来的Vj, 但是他要怀疑准确性,比如L1会想L2发给自己是否是正确的呢?那么就进入第三轮进行投票.因此跟在第2轮之后,L1会依次询问L3,4,5,6 ,问他们上一轮L2给他们发了什么,L1得到第二轮中L2->L3,L2->L4,L2->L5,L2-L6,再结合L2->L1,从5个里用majority函数决定L2发了啥,再依次遍历L3-6,然后L1完成第二轮的确认)
算法证明
详细的算法证明可参考:
定理1:对于任意m,如果有超过3m 个将军和最多m 个背叛者,算法OM(m) 满足条件IC1 和条件IC2。
引理1:对于任意m 和k ,如果有超过2k+m 个将军和最多k 个背叛者,那么算法OM(m) 满足IC2 (回顾下IC2 指的是,如果将军是忠诚的,所有的副官遵守将军命令)。
签名消息
签名消息在除了满足口头消息A1-A3 三点要求外还应该满足下面A4:
-
A4.
- (a)签名不可被伪造,一旦被篡改即可发现
- (b)任何人都可以验证将军签名的可靠性
choice() 来决定副官的选择:
-
当集合V 只包含了一个元素v ,那么choice(V)=v ;
-
choice(Φ)=RETREAT。
基于签名消息的算法
SM(m)算法:
初始化Vi=空集合
(1)将军签署命令并发给每个副官
(2)对于每个副官i :
(A)如果副官i 从发令者收到v:0 的消息,且还没有收到其他命令序列,那么:
(i)使Vi 为{v}
(ii)发送v:0:i 给其他所有副官
(B)如果副官i 收到消息v:0:j1:...:jk 且v 不在集合Vi 中则
(i)添加v 到Vi
(ii)如果k<m ,那么发送v:0:j1:...:jk:i 给每个不在j1,..,jk 中的副官
(3)对于每个副官i ,当不再收到消息,则遵守命令choice(Vi)
基于签名消息的算法证明
定理2:对于任意m,最多只有m 个背叛者情况下,算法SM(m) 解决拜占庭将军问题。
区块链与分布式系统
- 区块链的核心是一个点对点的分布式账本,此类账本具有加密安全性,且仅可追加内容,同时不可更改(很难),只有在对等身份成员之间达成共识或协议时才能更新
- 区块链可以定义为一个平台,在此平台上,对等点可以通过交易交换值,而不需要中央信任仲裁者。
一致性
一致性是指不信任节点之间的协议过程。
一致性机制所需满足的需求:
- 协议:全部可信节点制定同一值
- 有效性:所有可信节点的商定值必须与至少一个节点所提议的初始值相同
- 容错性:一致性算法应在能出现故障或恶意节点的情况下运行
- 完整性:任何节点都不可能做多次决策
一致性机制的类型:
- 基于拜占庭式的容错:不存在计算密集型操作,依赖于一个简单的、发布签名消息的节点方案
- 基于领导的一致性机制:节点实现领导选举机制,由获胜节点提供结果值
区块链的一般元素
- 地址:表示事务中收件人和发件人的唯一标识符,通常表示为公钥或派生自私钥。建议在每个事务中用新生成的地址,防止将交易链接到公共所有者,避免身份识别
- 事务:区块链的基本单元,表示地址间的值传输
- 区块:由多个交易和其他元素组成
- P2P网络:所有对等点之间的可以彼此通信、发送和接收消息
- 脚本或程序语言:交易脚本是节点的预定义集合,用于将令牌从一个地址转移到另一个地址,并执行各种其他功能
- 虚拟机:事务脚本的扩展,可运行图灵完备的代码
- 状态机:一个区块链可以看作一个状态转换机制
- 节点:可以生成并验证交易,同时进行挖掘。根据区块链类型及节点分配的角色,还可以执行其他功能
- 智能合约:智能合约运行于区块链之上,在满足某些条件时封装业务。区块链并不支持智能合约
区块链的特性
- **分布式一致性:**缺少中心信任机制授权的情况下,各方都能达成一致
- **交易验证:**节点发布交易基于预先确定的规则进行验证,有效的交易才能包含在区块中
- **智能合约平台:**区块链定义为一个平台,程序可以运行其上,并代表用户执行业务逻辑
- **在对等点间传输值:**允许通过令牌在用户之间传递值,令牌是值的载体
- **生成加密货币:**是一个可选的特性,为的是激励矿商
- **智能属性:**采用不可撤销的方式将资产与区块链联系起来,使任何人都无权占有、资产完全由个人控制、不可重复使用或双重拥有
- **安全提供商:**基于已证实的加密技术,确保数据的完整性和可用性
- **不变性:**区块链中的记录是不可变的
- **唯一性:**每个交易都是唯一的,且尚未被消费
- **智能合约:**区块链提供了一个有智能合约特性的平台,可视为区块链上的自主程序,可以封装业务逻辑和代码,以便下一步所需。智能合约同时实现了灵活性、可编程性、对于特定业务执行的特定操作,区块链用户可对此加以控制
区块链中的共识
-
工作量证明机制(PoW)
依赖于:在提出一个网络接受价值之前已经花费饿了足够的计算资源。用于比特币和其他加密货币。
-
权益证明(PoS)
理念:节点或用户在系统中具有足够的权益。如用户在系统中投入了足够的资金,因此,恶意行为获得的收益将超出执行系统攻击。应用于以太坊区块链中,生成并签订下一个区块的机会随着币龄而增加。
-
委托权益证明(DPoS)
对PoS的一种创新,每个节点都可以通过投票将交易的验证委托给其他节点。应用于比特股中。
-
流逝时间证明
使用可信执行环境(TEE)通过可靠的等待时间再领导选举过程中提供随机性和安全性。
-
基于保证金的共识
希望加入网络的节点在生成区块链之前存入保证金。
-
重要性证明
依赖于用户在系统中所拥有的权益份额,并监视用户对令牌的使用和移动,以建立信任和重要性级别。
-
联邦共识和联邦拜占庭共识
应用于恒星共识协议中,保留一组公开信任的对等点,并只传播由大多数受信节点验证的交易。
-
信誉机制
基于在网络上建立的声誉选择领导者,由其他成员投票实现。
-
实用拜占庭容错机制(PBFT)
实现了状态机的复制,并对拜占庭节点提供了容错机制。
基于区块链的去中心化
**分布式系统:**数据和计算是分布在多个节点上,计算不可能以并行方式执行,数据仅可在用户视为单一聚合系统的多个节点上进行复制。
**并行系统:**计算是由所有节点同步执行。
分布式系统:存在管理整个系统的中央权威机构,控制权分布在许多节点中。
**去中心化系统:**是节点不依赖与单个主节点的网络类型,且不存在中央权威机构。
去中心化方法
存在两种方法实现去中心化:非中介化和竞争
非中介化:不通过中介机构进行相应的活动,或消除中间人或中介机构,如C2C模式;不通过银行转账,而用区块链地址进行直接转账
竞争:一组服务提供者相互竞争,以便被系统选择进而提供有效服务。在区块链系统中,智能合约可以根据声誉、评分、评论和服务质量,从大量的提供者中选择一个外部的数据提供者。当然这并不是完全的去中心化,但允许智能合约根据标准作出自由选择
去中心化流程
不是所有的事务都需要去中心化的
去中心化需求条件评估:
去中心化的含义
去中心化系统可以是任何系统
去中心化所需的级别
可以是完全中介化或部分中介化
采用哪种区块链
可以选择比特币、以太坊等
采用哪种安全性机制
原子性机制,确保系统的完整性;声誉机制,支持系统中不同的受信度
区块链和完整的生态圈去中心化操作
去中心化的生态系统概览如下:

存储
数据可以直接存储在区块链中,即实现了去中心化操作,但存在一个缺点:区块链不适合存储大量的数据,如图像。
去中心化存储方案:
-
**分布式哈希表(DHT):**应用于BitTorrent,用户不会无限期的保存相关文件,如果节点脱离网络,则节点无法被检索到,除非该节点再次加入到网络,以使文件再次可用。
-
**Inter Planetary File System(IPFS)**拥有高可用性和链接稳定性,旨在通过替换HTTP协议提供一个去中心化的万维网。使用Kademlia DHT和merkle DAG(有向无环图)分别提供存储和搜索功能。
-
激励机制基于Filecoin协议,该协议向使用BitSwap机制存储数据的节点提供激励。 BitSwap机制允许节点保留一个简单的字节账本。
-
Ethereum包含自身的去中心化和分布式的生态系统,并使用集群存储和whisper协议进行通信。
-
Maidsafe致力于提供一个去中心化的万维网。
-
BigChainDB目的是提供一个可伸缩、快速和线性和伸缩的去中心化数据库,而不是传统的文件系统。
通信
去中心化网络方案:
-
Internet旨在建立一个去中心化的系统。该模型基于中央权威(服务提供者)的信任,用户并不负责管理其数据,甚至密码也可存储在受信的第三方系统上。有必要以某种方式向个别用户提供管理权限,确保用户可以访问数据,并且不依赖于第三方。(如IPFS)
-
**网状网络:**节点间可以直接对话,而不需要像服务提供商那样采用中心枢纽。例如Firechat,允许iphone用户在没有互联网的情况下以点对点的方式直接进行通信。
密码学与基本技术
区块链的不可篡改性基于密码学的算法实现
-
密码学发展简史
-
密码学数学基础
-
对称密码机制
-
非对称密码机制
-
Hash技术
哈希函数用于创建任意长度的输入字符串、固定长度的文摘,所以常用于数字签名和消息认证码中。
SHA256:输入消息大小小于264位。其中,块大小为512位,字大小为32位,输出为256位的文摘。
- 预处理算法:
a) 如果小于512位块尺寸,填充为512位块尺寸。
b) 将消息解析为消息块,确保消息及其填充内容划分为512位的相等快。
c) 设置初始哈希值,表示为8个32位的字,是前8个素数的平方根小数的前32位。
- 哈希计算步骤:
a) 每个消息块依次进行处理,需要64轮才能计算出全部哈希结果。其中,每一轮使用不同的常数,以确保没有两轮处于等同状态。
b) 设置消息轮询。
c) 初始化8个工作变量。
d) 计算中间哈希值。
e) 处理消息并生成输出哈希值。
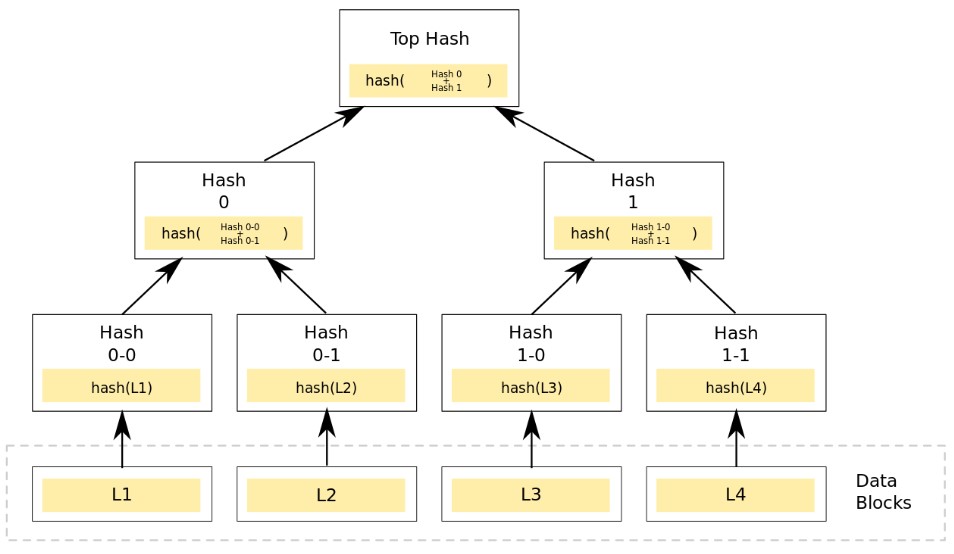
在p2p网络下载网络之前,先从可信的源获得文件的Merkle Tree树根。一旦获得了树根,就可以从其他不可信的源获取Merkle tree。通过可信的树根来检查接受到的Merkle Tree。如果Merkle Tree是损坏的或者虚假的,就从其他源获得另一个Merkle Tree,直到获得一个与可信树根匹配的Merkle Tree。
-
特点:
- MT大多数是二叉树,也可以多叉树,具有树结构的所有特点
- 叶子节点的value是数据集合的单元数据或者单元数据HASH
- 非叶子节点的value是根据它下面所有的叶子节点值,然后按照Hash算法计算而得出的
-
优点:可以直接下载并立即验证Merkle Tree的一个分支。因为可以将文件切分成小的数据块,这样如果有一块数据损坏,仅仅重新下载这个数据块就行了。
-
基本密码技术的应用
EC-DH交换密钥
EC-DES签名
共识算法
可参考:
共识机制
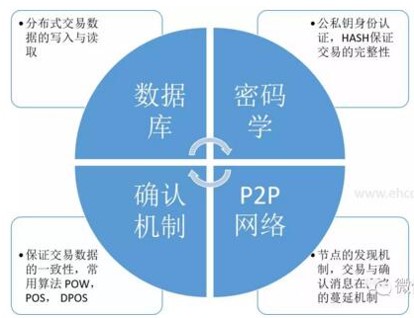
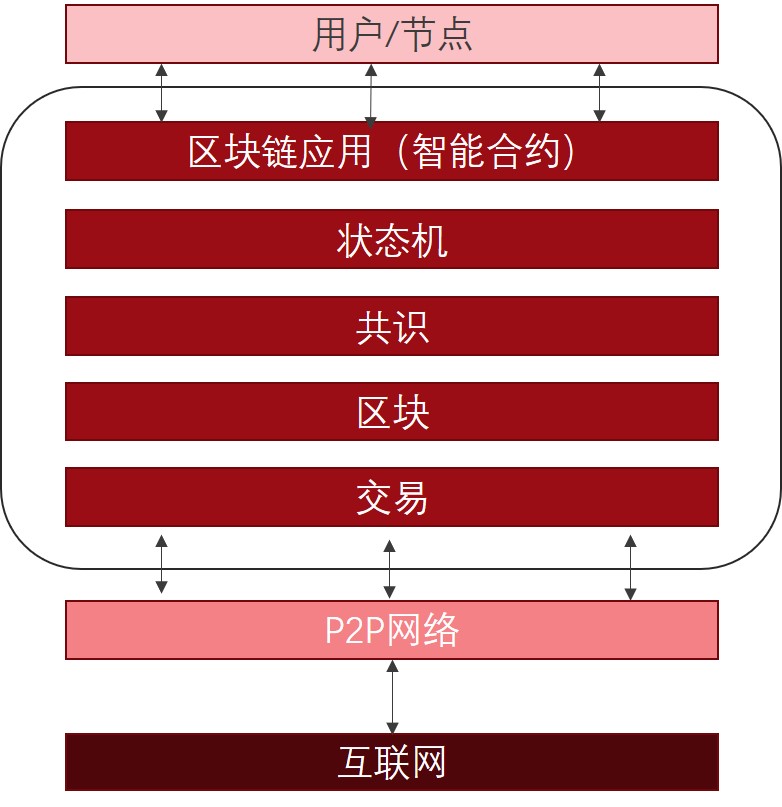
区块链的底层由四部分构成
- 分布式数据库:用来存储以往和将来的交易数据
- 密码学:公钥私钥体系用来确认交易双方的身份
- P2P网络:用来广播和蔓延各类消息(如节点的加入消息、节点失效消息、得到挖矿数据的消息)
- 共识机制:用来决定节点记账权利
区块链系统的核心是系统节点竞争记账,这个竞争过程称为共识机制
共识机制在区块链中扮演着核心地位,共识机制决定了谁有记账的权利,以及记账权利的选择过程和理由
- 共识机制:区块链事务达成分布式共识的算法
不同的虚拟货币采用不同的共识机制,常见的共识机制如POW、POS、DPOS、PBFT等
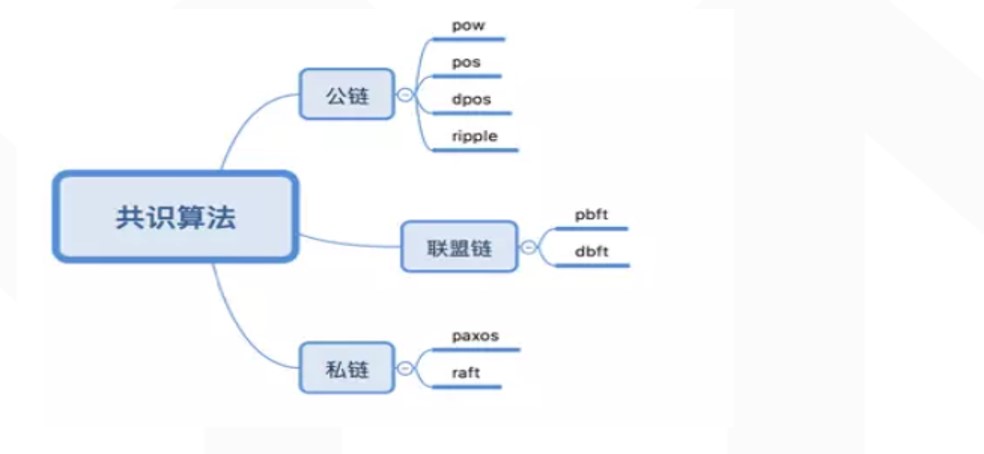
PoW
POW:Proof of work,工作量证明机制
POW工作量证明就是我们所熟悉的挖矿,通过与或运算,计算出一个满足规则的随机数,即获得本次记账权,发出本轮所需要记录的数据,全网其他节点验证后一起存储。这种证明方式的一个显著特征是往往需要很大的工作量才能拿到指定成果,但是这个成果很容易验证
POW工作量证明的三要素:①工作量证明函数 ②Merkle树 ③难度值
①工作量证明函数
1.输入x可以是任意长度的字符串
2.输出结果即H(x)的长度是固定的
3.计算H(x)的过程是高效的
函数还需要免碰撞,即不会出现 x ≠ y ,但是 H(x)=H(y)。但是这个特点在理论上并不成立,对于SHA256算法,会有2^256种输出,进行2^256+1次输出,那么根据鸽巢原理,一定会产生一次碰撞。
但是从概率的角度看,随机生成K个数,他们不同的概率为 (N-1)/N × (N-2)/N × …… × (N-(k-2) )/N × (N-(k-1))/N = e-k(k-1)/2N
因此,碰撞的概率为 1-e-k(k-1)/2N
因此,从概率的角度看,sha256进行2^130次输入就会有99%的可能发生一次碰撞
不过,假设一台计算机以每秒10000次的速度进行哈希运算,要经过10^27年才能完成2^128次hash运算
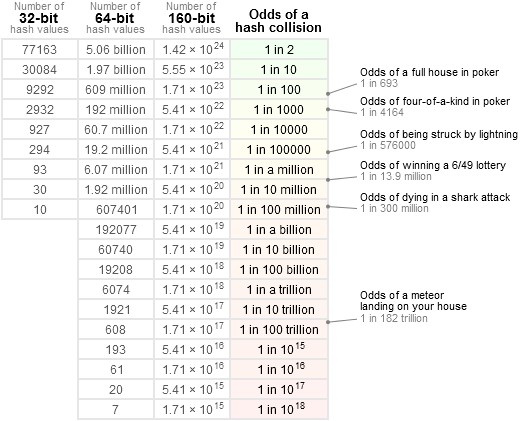
如图为不同位发生hash碰撞的可能性,最右边是发生hash碰撞的可能性,左边是经过多少个数之后可能达到发生的可能性。
对于一个给定的输出结果H(x),想要逆推出输入x,在计算上是不可能的。
不存在比穷举更好的方法,可以使哈希结果H(x)落在特定范围。

Block Hash = hash(本页内容,Pre Hash,时间戳)
|
|
②Merkle树
Merkle树一般用于完整性验证处理。Merkle哈希树是一类基于哈希值的二叉树或多叉树,其子节点上的值通常为数据库的哈希值,而非叶子节点上的值该将该节点的所有子节点的组合结果的哈希值。将Merkle Root存入区块头里,Merkle Tree 存入区块体里。
节点生成一笔筹币交易,对于4个交易记录L1,L2,L3,L4,分别计算hash(L1),hash(L2),hash(L3),hash(L4);对于hash0=hash(hash0-0+hash0-1) 和 hash1=hash(hash1-0 + hash1-1);计算出根节点的hash值top hash,topHash=hash(hash0+hash1)。
然后将Merkle树root的top hash值存入区块链头中,如下图
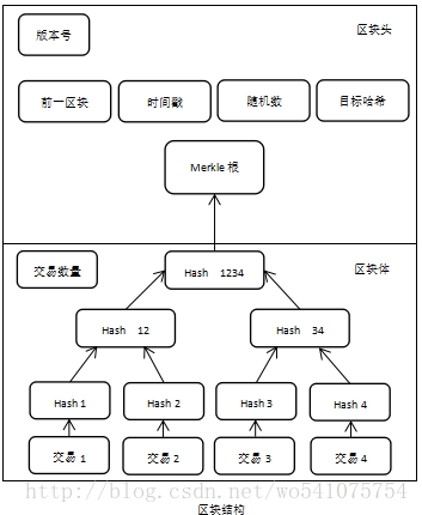
区块链中的Merkle树为二叉树,用于存储交易信息。每个交易两两配对,构成Merkle树的子节点,进而生成整个Merkle树。Merkle树使得用户可以通过从区块头得到的Merkle树根和别的用户所提供的中间哈希值列表去验证某个交易是否包含在区块中。提供中间哈希值的用户并不需要是可信的,因为伪造区块头的代价很高,而中间哈希值如果伪造的话会导致验证失败。
SPV:简化支付验证(Simplified Payment Verification),轻钱包并不保存完整的区块链,而是只保存每一个区块的区块头。区块体保存了完整的交易信息,而交易信息需要的存储量大部分都是交易头的千倍以上。所以,如果只保存交易头,就可以极大的减少本地客户端存储的区块链信息。
在交易时,发出一个MerkleBlock消息,包含区块头和一条连接目标交易与Merkle根的Merkle路径
若需验证该交易,即可通过其Merkle路径与交易hash确定一个新的Merkle Root,将其与原root相比即可。
参考:
假如有交易改变,则整个树枝会发生改变
定位的时间为O(log(n)),即二叉树的查找时间
③难度值
- 新难度值 = 旧难度值 * (20160分钟 / 最近的2016个区块花费的时长)
新难度值解析:撇开就难度值,按比特币理想值情况每10分钟出块的速度,过去2016个块的总花费时间接近20160分钟,这样,这个值永远趋于1。
若过去2016个区块花费时长少于20160分,那么这个系数会小于1,否则,会大于1。
难度值越大,越难挖。因为20160分大约为14天,而比特币网络大约14天调整一次难度值。
比特币的难度和出块速度将成反比例适当调整出块速度。
目标值 = 最大目标值 / 难度值
最大目标值:一个固定数(恒量,十六进制前8位0后面56位1,即32bit0)0x00000000FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
即前N bit为0
目标值解析:若过去2016个区块花费时长少于20160分,那么难度值会变小,目标值将会被调小些;否则,目标值会被调大。
查找块的平均时间可以通过如下方式计算:
time = difficulty * 2**32 / hashrate难度值 = time (s) * hashrate (hash / s ) / (2**32)
新难度值 / 旧难度值 = 新算力 / 旧算力
如果难度为1的话,大约是每秒钟7 Mhashes
例:
计算目标值,5min产生一个区块,sha256算法,算力 400M hash/s.
一个正确区块被计算,需要进行 (5*60)s * 400M hash/s = 120,000 M hash
假如计算一个区块头需要1M hash , 则 计算正确头的几率为 1 / (2^17) ,(120000 ≈ 2^17)
所以, (2^(256-17)) / 2^256 == 1 / 2^17
所以, 目标值为: 0b0……………………011……
|-17bit0-||--(256-17)bit--
POW工作量证明流程
流程如下图:
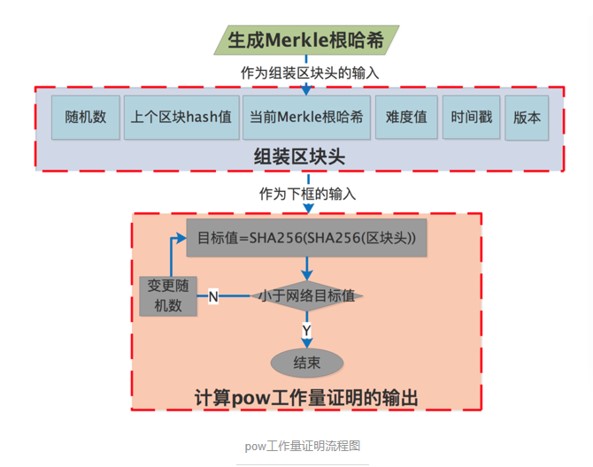
- 生成Merkle根哈希
- 组装区块头
- 计算出工作量证明的输出
!!!:区块头里的随机数即是nonce
1.如上
2.组装区块头:块头将被作为计算出工作量证明输出的一个输入参数,因此第一部计算出来的Merkle根哈希和区块头的其他组成部分组装成区块头
3.计算出工作量证明的输出:
i) 工作量证明的输出 = SHA256( SHA256(区块头) )
ii) if (工作量证明的输出 < 目标值 ),证明工作量完成
iii) if (工作量证明的输出 >= 目标值),变更随机数(Nonce),递归 i 的逻辑,继续与目标值比对
- 对这个值进行两次SHA256运算,为什么要两次,这是因为SHA1在2017年被攻破,采用的方法是birthday collision attack。社区觉得SHA2被攻破也是时间的问题,而抵御birthday collision attack的有效方法为双重哈希算法,当然这种说法只是网上传言,没有得到具体确认。
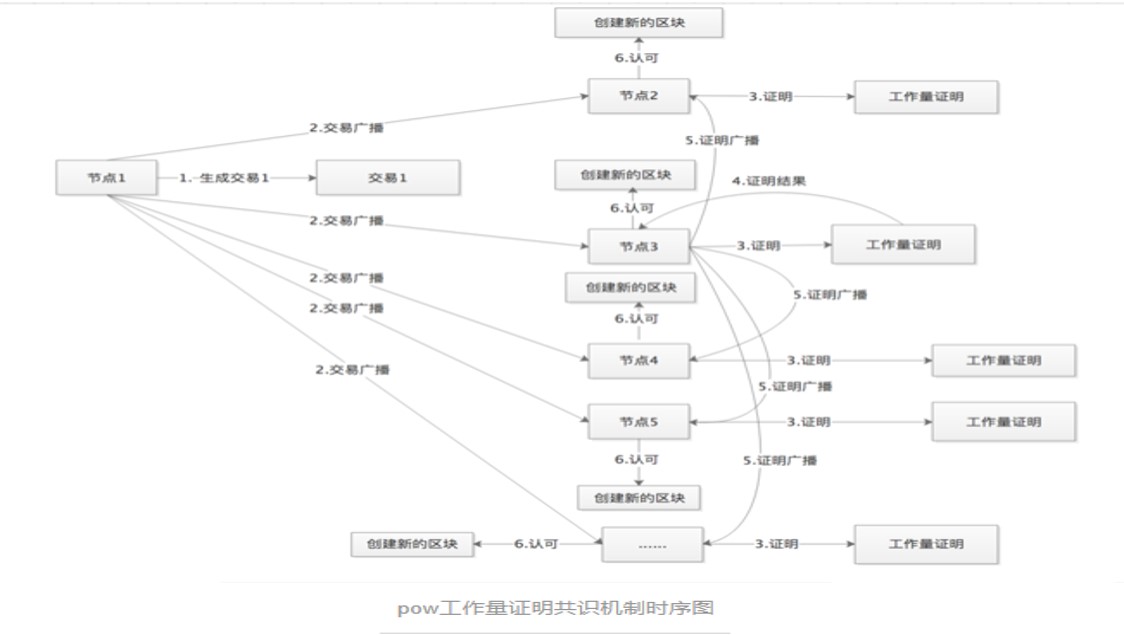
客户端产生新的交易,向全网广播
每个节点收到请求,将交易纳入区块
每个节点通过pow工作量证明
当某个节点找到了证明,向全网广播
当且仅当该区块的交易是有效的且在之前中未存在的,其他节点才认同该区块的有效性
接受该区块且在该区块的末尾制造新的区块
-
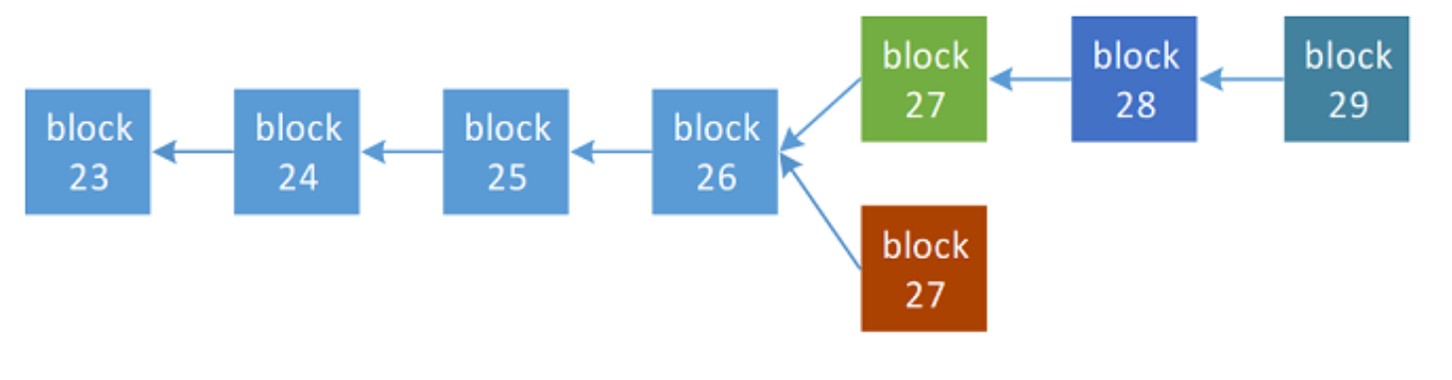
节点总是认为最长的链是正确的链,并致力于在最长的链上进行扩展。
-
如果两个节点同时完成PoW过程并广播了不一样的区块,有的节点收到其中一个,而有的节点先会收到另一个。
-
这种情况下,首先收到的区块会被节点作为下一个区块添加到链上,同时也会保存后到的区块。
-
当下一个区块来临时,就会知道哪一个区块是比较长的,然后切换到较长的区块链上。
- 新交易的广播不一定要到达每一个节点,只要到达足够多的节点,这些节点就会在一定时间内将交易打包到区块中
- 区块的广播也是允许丢包的,如果节点没有收到某一个区块,当下一个区块到来时,该节点发现新区块的prevHash不是目前最后一个区块,就会去请求丢失的区块
- 因为做出工作量证明的节点上没有未建块的交易,从而有可能产生空块
POW的优缺点
- **优点:**完全去中心化,节点自由进出
- **缺点:**目前bitcoin已经吸引了全球大部分的算力,其他再用POW共识机制的区块链应用很难获得相同算力来保障自身的安全;挖矿造成大量的资源浪费;共识达成的周期较长,不适合商业应用
POS
POS:权益证明机制(Proof of Stake),是Pow的一种升级共识机制,根据每个节点所占代币的比例和时间,等比例的降低挖矿难度,从而加快找到随机数的速度。
若Pow主要比拼的是算力,那么Pos则是比拼余额。通俗说就是当手里的币越多,挖到一个块的概率越大
POS合格区块可以表述为:F(Timestamp) = Target * Balance,与POW的F(Nonce) < Target 相比,式子左边的搜索空间由Nonce 变成 Timestamp,Nonce值域是无限的,而Timestamp的值域是极其有限的,一个合格的区块时间必须在前一个区块时间的规定范围之内,时间太早或者太超前的区块都不会被其他节点接纳。式子右边的目标值引入一个乘积因子余额,课件余额越大,整体目标值(Target*Balance)越大,越容易找到一个区块。因为Timestamp 有限,POS铸造区块成功率主要与Balance有关。
Peercoin(PPC)
PPC是POS的一种具体的实现方式
PPC是从中本聪所创造的BTC衍生出来的一种P2P的电子密码货币,以权益证明(Proof of Stake,以下简称PoS)取代工作量证明(Proof of Work,以下简称PoW)来维护网络安全。在这种混合设计中,PoW主要在最初的采矿阶段起作用。长远来看,PPC网络的安全并不依赖能源的消耗。因此PPC是一种节能而有成本优势的P2P电子密码货币。
PoS是基于币龄(coin age)并由通过与 BTC类似的由每个节点散列运算产生的,只是其搜索空间被限制了。区块链的历史及交易结算是通过一个中心化广播检查机制得到进一步保护。
要掌握Peercoin的POS机制,需要重点理解Sunny King专门为PPC设计的几个核心概念:
-
Coinage
币龄,也叫币天。假如1.5个币存在于区块链中10天,币龄数值为:Coinage = 1.5 * 10 = 15
PPC采用币龄,而不是直接采用余额(Balance)来计算。一个UTXO(未花费的交易输出)一旦被花费,其币龄被清零,新的UTXO币龄从0开始算起
-
stakeReward
权益激励,俗称获得利息,计算公式如下:
stakeReward = nCoinAge*33/(365*33+8)*0.01*COIN,公式可简化未:
stakeReward = (0.01 * nCoinAge /365) * COIN其中,nCoinAge是CoinStake所有输入的币龄总和,由公式可知收益按1%年率计算。理想状态下,假设所有的币全年都参与挖矿,代币总量每年有1%通胀率,这一设计为很多人所诟病,而且,这一设计并不能激励矿工积极参与挖矿以维护区块链的安全,因为如果不考虑手续费,持币用户每隔几个月打开节点铸币,或者实时在线铸币,理论上收益都是一样的。
-
stakeMinAge
POS系统也存在51%币龄攻击风险,为了增加攻击难度,Sunny King对每一笔UTXO的铸币资格做了最小年龄(stakeMinAge)限制:一个UTXO在区块链存在的时间小于stakeMinAge则没有铸币资格,PPC最小币龄为8小时。
POS2.0
黑币社区认为币龄可能会被恶意的节点滥用以获得更高的网络权重并成功实施双花攻击,于是发布POS2.0白皮书,对PPC做了几个细节优化,解决了一些潜在的安全问题,其中最重要的改进是用余额代替币龄,合格区块的条件由:
F(Timastamp) < Target * 币数 * 币的年龄
变为: F(Timastamp) < Target * 币数
如此一来,一笔UTXO无论放置多久其锻造区块的能力不变,此举可激励节点必须更多的保持在线进行铸币,提高系统安全性,将攻击途径减少到最低限度,并且能够显著提高网络保持运行的节点数量。
POS3.0
黑币社区后来进一步升级,推出POS3.0版本,对交易手续费,难度调整做了一些优化,其中最显著的改变是将1%年利率奖励机制变为固定数额奖励(每个区块固定奖励1.5BLK),此举不但降低代币通胀率(考虑到会有代币永久丢失,低额奖励机制回归总量恒定的设计思路),同时意味着持币节点必须实时在线才能获得收益。
POS的优缺点
- 优点:在一定程度上缩短了共识达成的时间
- 缺点:还需要挖矿,本质上没有解决商业应用的痛点
DPoS
DPOS:股份授权股份证明(Delegated Proof-Of-Stake)
比特股(Bitshares)项目于2013年8月开始启动,对区块链做了很多改造,并引入许多新概念和特征,尤其令人眼花缭乱的 Bitshares X、多态数字资产交易平台、资产锚定等新名词,一时令人无比兴奋而又困惑。此时POW和POS都已成功运行许久,彼此优劣已被反复讨论,两大阵营时至今日依然争论不休。按照项目规划,比特股对交易容量和区块速度有极高要求,显然POW或POS都达不到要求,于是比特股发明了一种新的共识机制DPOS,即股份授权股权证明。
DPOS是 PoS 的进化方案,在常规 PoW 和 PoS 中,一大影响效率之处在于任何一个新加入的 Block,都需要被整个网络所有节点做确认。
DPoS 优化方案
通过不同的策略,不定时的选中一小群节点,这一小群节点做新区块的创建,验证,签名和相互监督,这样就大幅度的减少了区块创建和确认所需要消耗的时间和算力成本。
DPOS机制涉及的问题
1. 持有股票
直接在交易平台上购买比特股即可
2. 成为代表
成为一名代表,你必须在网络上注册你的公钥,分配到一个32位的特有标识符
3. 授权选票
每个钱包有一个参数设置窗口,在该窗口里用户可以选择一个或更多的代表,并将其分级
一般情况下,用户不会创建特别以投票为目的的交易,因为那将耗费他们一笔交易费
4. 保持代表诚实
每个钱包将显示一个状态指示器,让用户知道他们的代表表现如何
5. 抵抗攻击
在抵抗攻击上,因为前100名代表所获得的权利权是相同的,每名代表都有一份相等的投票权,并且,如果当前记账节点不记账则由下一个记账人记账,因此无法通过获得超过1%的选票而将权力集中到一个单一代表上,毕竟同时收买100给代表的难度很大。同时,每名代表的标识是其公钥而非IP地址,使得DOS攻击目标更为困难(难定位)
6. 代表竞选
选出的代表拥有提出改变网络参数的特权,包括交易费用、区块大小、见证人费用和区块区间
DPOS遵循的基本原则
- 持股人依据所持股份行使表决权,而不是依赖挖矿竞争记账权
- 最大化持股人的盈利
- 最小化维护网络安全的费用
- 最大化网络的效能
- 最小化运行网络的成本(带宽、CPU等)
DPOS的优缺点
-
能耗更低:DPoS机制将节点数量进一步减少,在保证网络安全的前提下,整个网络的能耗进一步降低,网络运行成本最低。
-
更快的确认速度:每个区块的时间为10秒,一笔交易(在得到6-10个确认后)大概1分钟,一个完整的区块的周期大概仅仅需要数分钟。而PoW机制下产生一个区块需要10分钟,一笔交易完成需要数个小时。
-
在一定程度上解决了拒绝服务攻击和潜在作恶节点联合作恶的问题。
-
投票的积极性并不高:绝大多数持股人从未参与投票。这是因为投票需要时间、精力以及技能,而这恰恰是大多数投资者所缺乏的。
-
垄断性高:DPoS延续了PoS的弊端,只有持币者才可以获得区块链奖励,其实这就带来了一种制度性门槛,最终导致DPoS币的流动性大大减少,穷者越穷,富者越富。
PBFT
PBFT:实用拜占庭容错算法(Practical Byzantine Fault Tolerance)
以往的区块链项目都以虚拟币为内核,而记录数据的应用不需要币机制模型。这个时候,Hyper Ledger(超级账本)应景而生,它是由Linux基金会组织牵头的项目,是一个旨在推动区块链数字技术和交易验证的开源项目。这个分布式账本技术是完全共享、透明和去中心化的,非常适合于金融行业的应用,以及其他的例如制造、银行、保险、物联网等无数个其他行业。
- PBFT是Hyper Ledger中使用的共识算法
PBFT的算法基本流程
假设有f个恶意节点,则保证系统正常运作,需要有2f+1个正常节点,总结点数为3f+1
- 客户端发送请求给主节点
- 主节点广播请求给其他节点,节点执行pbft算法的三阶段共识流程
- 节点处理完三阶段流程后,返回消息给客户端
- 客户端收到来自f+1个节点相同消息后,代表共识已经正确完成
如图:
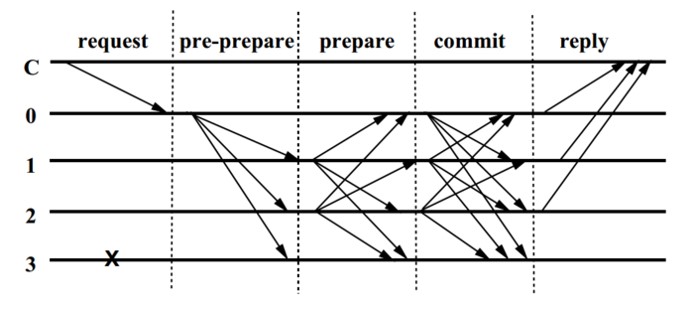
C为Client,pre-prepare为预准备阶段,prepare为准备阶段,commit为提交阶段
R在一个视图里,一个是主节点,其余的都叫做备份节点,如图主节点为0,即Client首先请求主节点负责将客户端的请求排好序,然后按序发给备份节点
但是主节点可能是拜占庭的:他可能会给不同的请求编上相同的序号,或者不去分配序号,后者让相邻序号不连续。
备份节点应当有职责主动检查这些序号的合法性,并能通过timeout机制检测到主节点是否已经宕机。
当出现异常情况下,就会出发视图更换view change协议来选举出新的主节点
Requset阶段
在此阶段,客户端c向主节点p发送请求,<Request,operation,timestamp,clientID>
operation:为请求具体操作
timestamp:请求时客户端追加的时间戳
clientID:客户端标识
Requset:包含消息内容message,以及信息摘要d(message)
客户端对请求进行签名
PBFT算法预备(Pre-Prepare)
在预准备阶段,主节点对签名进行校验,并分配一个序列号n给收到的请求,然后向所有备份节点群发预准备消息,预准备消息的格式为:< <Pre-Prepare,v,n,d> , m >
v是视图编号
n是序列号
m是客户端发送的请求消息
d是请求消息m的摘要
预准备消息的目的是作为一种证明,确定该请求是在视图v中被赋予了序号n
在视图变更的过程中可以追索请求
请求本身是不包含在预准备消息中,这样能使预准备消息足够小
Prepare
当节点收到pre-prepare消息后,会选择接收与否
满足下列条件时,各个备份节点才会接收一个预准备消息:①请求和预准备消息的签名正确,并且d与m的摘要一致;②当前视图编号是v;③该备份节点从未在视图v中接收过序号为n但是摘要d不同的消息m;④预准备消息的序号n必须在水线上下限h和H之间,水线存在的意义在于防止一个失效节点用一个很大的序号消耗序号空间。
如果备份节点i接受了预准备消息< <Pre-Prepare,v,n,d> , m >,则进入准备阶段。
在准备阶段的同时,该节点向所有副本节点发送准备消息 < Prepare,v,n,d,i >,并且将预准备消息和准备消息写入自己的消息日志,可丢弃非法请求(即非法预准备消息)
节点(包括主节点)收到prepare消息后,进行验证prepare消息签名是否正确,视图编号是否一致,消息序号是否满足水线限制,若验证通过则将消息写入消息日志中。
副本节点i将(m,v,n,i)记入消息日志中,其中m是请求内容,预准备消息m在视图v中的编号n,以及2f个从不同副本节点收到的与预准备消息一致的准备消息
每个副本节点验证预准备和准备消息的一致性主要检查:视图编号v、消息序号n和摘要d
Commit
当prepared (m,v,n,i)条件为真的时候,
-
副本i生成确认消息
-
追加到本地消息日志文件
-
将确认消息向其他副本节点
-
广播进入了确认阶段 < COMMIT,v,n,D(m),i>
每个副本节点接收Commit消息的条件是:
- Commit消息签名正确
- 上一阶段请求的摘要也是D(m)
- 消息的视图编号与节点的当前视图编号一致
- 消息的序号n满足水线条件,在h和H之间
一旦确认消息的接受条件满足了,则该副本节点将确认消息写入消息日志中
当节点收到2f+1(包括自身)个不同节点发送过来的Commit消息之后,进入Commit-local(m,v,n)状态,且所有序号小于n的请求都被处理,则执行客户端请求m中所要求的服务操作
保证在节点中提交的任意一个客户端请求,最终哦都会在另外2f个节点中被提交到本地的,并确保所有正常节点以同样顺序执行所有请求,这样就保证了算法的正确性
Reply
同时将执行结果发送给客户端 <Reply ,v,t,c,i,r>,r为请求操作结果
如果客户端收到f+1个相同的Reply消息,说明客户端发起的请求已经达到全网共识,否则客户端需要判断是否重新发送请求给主节点
副本节点会把时间戳比已回复时间戳更小的请求丢弃,以保证请求只会被执行一次
PBFT 检查点 (checkpoint)
如何清除历史请求的记录消息?
在执行完多条请求K(例如:100条)后执行一次状态同步,即发送CheckPoint消息。<CheckPoint, n, d, i>,n是当前节点所保留的最后一个视图请求编号,d是对当前状态的一个摘要,该CheckPoint消息记录到log中。
如果副本节点i收到了2f+1个验证过的CheckPoint消息,则清除先前日志中的消息,并以n作为当前一个stable checkpoint。
-
stable checkpoint(稳定检查点)呢?
大部分节点(2f+1)已经共识完成的最大请求序号。比如系统有4个节点,三个节点都已经共识完了的请求编号是213.那么这个213就是stable checkpoint
实际上当副本节点i向其他节点发出CheckPoint消息后,其他节点有可能还没有完成K条请求,所以不会立即对i的请求作出响应,它还会按照自己的节奏,向前行进。此时发出的CheckPoint未能形成stable,为防止i的处理请求过快,设置一个高低水位区间[h, H]来解决这个问题, 低水位h等于上一个stable checkpoint编号,高水位H = h + L,其中L是我们指定的数值(如100,或200), 当副本节点i处理请求超过高水位H时,就会停止脚步,等待stable checkpoint发生变化,再继续前进。
算法视图变更
每个副节点维持一个计数器。备份节点在接收到一个有效请求,但是还没有执行它时,会查看计时器是否在运行,如果没有,那么它将启动计时器;当请求被执行时就把计时器停止。
如果计时器超时,将会把视图变更的消息向全网广播。在主节点失效的时候仍然保证系统的活性,防止备份节点无期限地等待请求的执行。需要确保在新的view中如何来延续上一个view最终的状态, 比如给这时来的新请求的编号,比如如何处理上一个view还没来得及完全处理好的请求
计时器超时或发现作恶,副节点生成 view-change 消息 <VIEW-CHANGE,v+1,n,C,P,i>,最近一次的稳定检查点对应的请求的序列号 n,C 是证明该检查点稳定性的 2f+1 个 checkpoint 消息的集合,P 是 Pm 的集合,其中 m 是副节点 i 中的序列号大于 n 的等待提交和执行的客户端请求 m,每个 Pm 包含了如下的信息:①pre-prepare 消息;②2f 个由其他副节点签名的跟 pre-prepare 消息匹配的、有效的 prepare 消息;
此时,节点需要:
记录到本地日志文件中;
同时广播给其他节点;
要求替换掉主节点,变更到下一个视图 v+1;
- 注意,在视图变更期间,除了 checkpoint、view-change 和 newview 消息之外,备份节点 i 是不会接受其他消息的
在节点收到更换节点消息时,各个节点会收集视图变更信息,并发送确认给 view v+1 中的主节点。
(v+1 中的主节点可能是轮换产生,也可能选举产生)
新的主节点接收到 2f 个有效的 view-change 消息之后,发送自己签名σp' 的 new-view 消息<NEW-VIEW, v+1, V, O> ,V是主节点收到的2f+1个有效的VIEW-CHANGE消息 ,O是主节点重新发起的未经完成的PRE-PREPARE消息集合
-
找到所有节点的共同的稳定检查点h。
-
在h和h+L之间,如果存在n消息,则创建<<PRE-PREPARE, v+1, n, d>, m>消息。否则创建一个空的PRE-PREPARE消息,即:<<PRE-PREPARE, v+1, n, d(null)>, m(null)>, m(null)空消息,d(null)空消息摘要。
对于节点v+1,提议系统内所有节点切换到下一个视图 v+1,同时接受自己成为新的主节点
副节点收到要求将视图变更为 v+1 的 new-vew 消息后,确认消息有效,接受该 new-view 消息,记录到本地消息文件中,同时将视图更换到新的视图v+1,副节点把 new-view 中携带的由新的主节点重新生成的 pre-prepare 消息追加记录到本地的消息日志中,按照检查点协议进行垃圾回收,删除比较老的消息
对于 new-vew 消息中集合 O 中携带的所有由新主节点生成的新的 pre-prepare 消息,备份节点都会生成相应的 prepare 消息,记录到本地日志文件中,转发给其他节点,即对这些未处理的请求在新的视图中重新执行一遍三阶段协议,保证视图切换过程中未处理的请求能够重新被处理。
-
节点选出一个checkpoint作为新view处理请求的起始状态checkpoint就是当前节点处理的最新请求序号。
-
checkpoint就是当前节点处理的最新请求序号。 前文已经提到主节点收到请求是会给请求记录编号的。比如一个节点正在共识的一个请求编号是101,那么对于这个节点,它的checkpoint就是101
-
stable checkpoint(稳定检查点)呢?
大部分节点(2f+1)已经共识完成的最大请求序号。比如系统有4个节点,三个节点都已经共识完了的请求编号是213.那么这个213就是stable checkpoint。checkpoint的最大目的时减少内存占用。
当检查点被证明是稳定后,节点会把本地消息日志中的消息中客户端请求序列号小于或者等于 n 的消息(pre-prepare、prepare、commit 消息)都删掉。同时,它会删掉旧的检查点和 checkpoint 消息。
RAFT
RAFT最初是一个用于管理复制日志的共识算法,它是一个为真实世界应用建立的协议,主要注重协议的落地性和可理解性,RAFT是在非拜占庭故障下达成共识的强一致协议
Raft算法包含三种角色,分别是:跟随者(follower),候选人(candidate)和领导者(leader)。一个节点在某一时刻只能是这三种状态的其中一种,这三种角色是可以随着时间和条件的变化而互相转换的。
所有的节点初始状态都为follower,超时未收到心跳包的follower将变身candidate并广播投票请求,获得多数投票的节点将化身leader,这一轮投票的过程是谁先发出谁有利,每个节点只会给出一次投票,leader节点周期性给其他节点发送心跳包,leader节点失效将会引发新一轮的投票过程。
Raft阶段主要分为两个,首先是leader选举过程,然后在选举出来的leader基础上进行正常操作,比如日志复制、记账等。
- 关于RAFT的较详细的动画,可访问 http://thesecretlivesofdata.com/raft/
选举流程
RAFT的leader选举流程:
1)任何一个服务器都可以成为一个候选者candidate,它向其他服务器follower发出要求选举自己的请求。
2)其他服务器同意了,发出OK。注意,如果在这个过程中,有一个follower宕机,没有收到请求选举的要求,此时候选者可以自己选自己,只要达到N/2+1的大多数票,候选人还是可以成为leader的。
3)这样这个候选者就成为了leader领导人,它可以向选民也就是follower发出指令,比如进行记账。
4)以后通过心跳进行记账的通知。
5)一旦这个leader崩溃了,那么follower中有一个成为候选者,并发出邀票选举。
6)follower同意后,其成为leader,继续承担记账等指导工作。
记账过程
Raft的记账过程按以下步骤完成:
1)假设leader领导人已经选出,这时客户端发出增加一个日志的要求;
2)leader要求follower遵从他的指令,都将这个新的日志内容追加到他们各自日志中;
3)大多数follower服务器将交易记录写入账本后,确认追加成功,发出确认成功信息;
4)在下一个心跳中,leader会通知所有follower更新确认的项目。
对于每个新的交易记录,重复上述过程
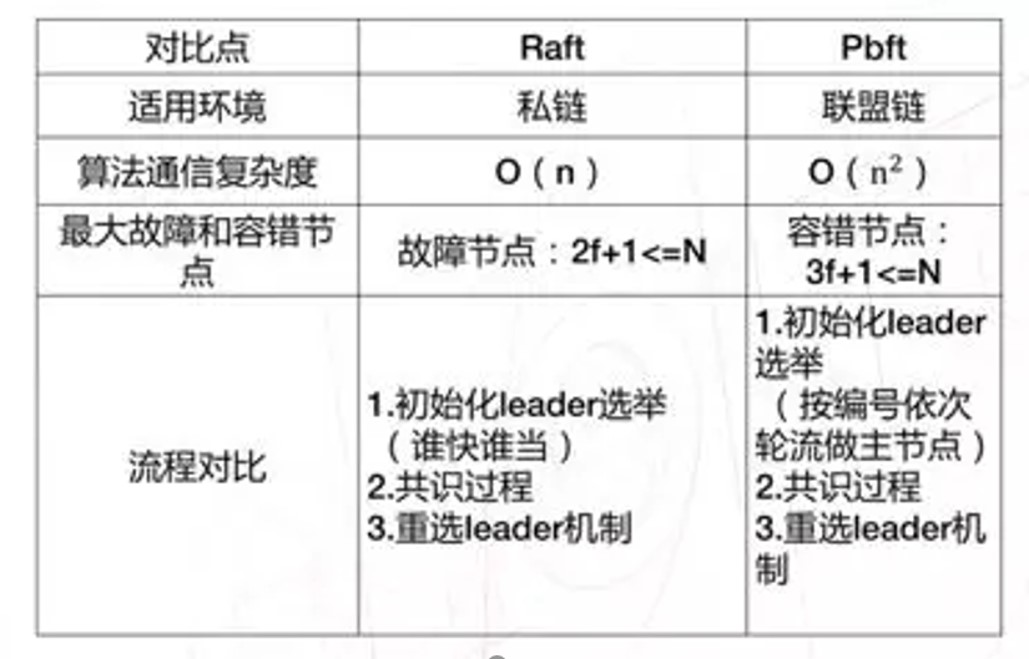
RAFT和PBFT对比
一个团队一定会有一个老大和普通成员。对于raft算法,共识过程就是:只要老大还没挂,老大说什么,我们(团队普通成员)就做什么,坚决执行。那什么时候重新老大呢?只有当老大挂了才重选老大,不然生是老大的人,死是老大的鬼。
对于pbft算法,共识过程就是:老大向我发送命令时,当我认为老大的命令是有问题时,我会拒绝执行。就算我认为老大的命令是对的,我还会问下团队的其它成员老大的命令是否是对的,只有大多数人(2f+1)都认为老大的命令是对的时候,我才会去执行命令。那什么时候重选老大呢?老大挂了当然要重选,如果大多数人都认为老大不称职或者有问题时,我们也会重新选择老大。
1.raft算法从节点不会拒绝主节点的请求,而pbft算法从节点在某些情况下会拒绝主节点的请求 ;
2.raft算法只能容错故障节点,并且最大容错节点数为(n-1)/2,而pbft算法能容错故障节点和作恶节点,最大容错节点数为(n-1)/3。
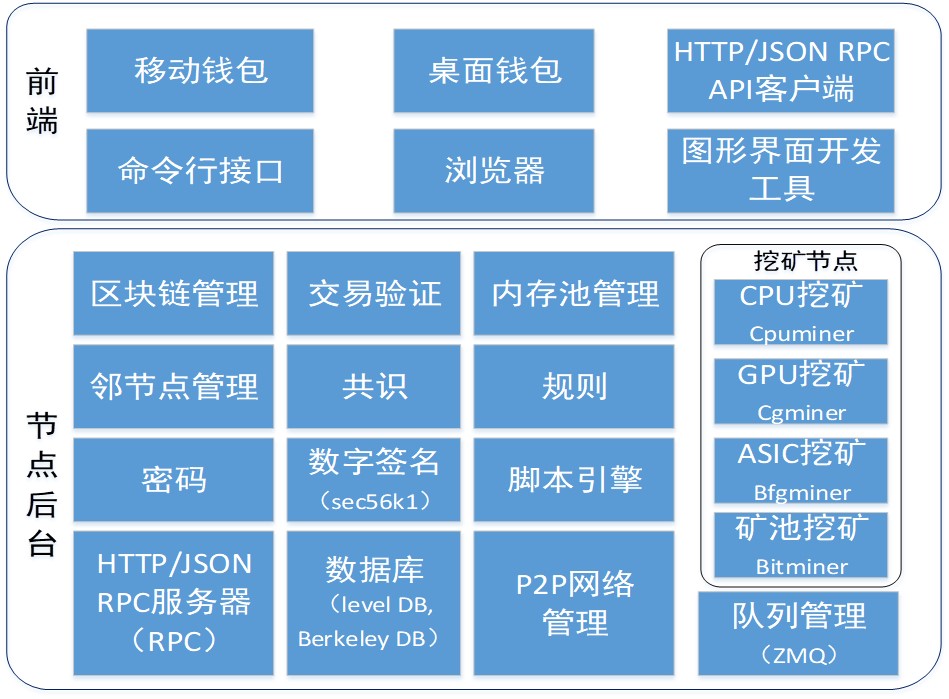
区块链架构
比特币
区块链1.0
区块链1.0是可编程货币,是与转账、汇款和数字化支付相关的密码学货币应用,目标是实现货币的去中心化与支付手段。比特币是区块链1.0最典型的代表, 区块链的发展催生了大量的货币交易平台,实现了货币的部分职能,能够实现货品交易。
比特币钱包:
- 移动钱包
- 桌面钱包
- 互联网钱包
- 纸钱包

优势
- 利于并行
- 可回溯
- 避免数据膨胀
缺点
- 查余额时必须回溯查询一大堆交易信息,浪费大量时间和资源
以太坊
区块链2.0
区块链2.0是可编程金融,是经济、市场和金融领域的区块链应用,核心理念是把区块链作为一个可编程的分布式信用基础设施,支撑智能合约应用,以与过去比特币区块链作为一个虚拟货币支撑平台区别开来。
以太坊:数字代币,基于智能合约
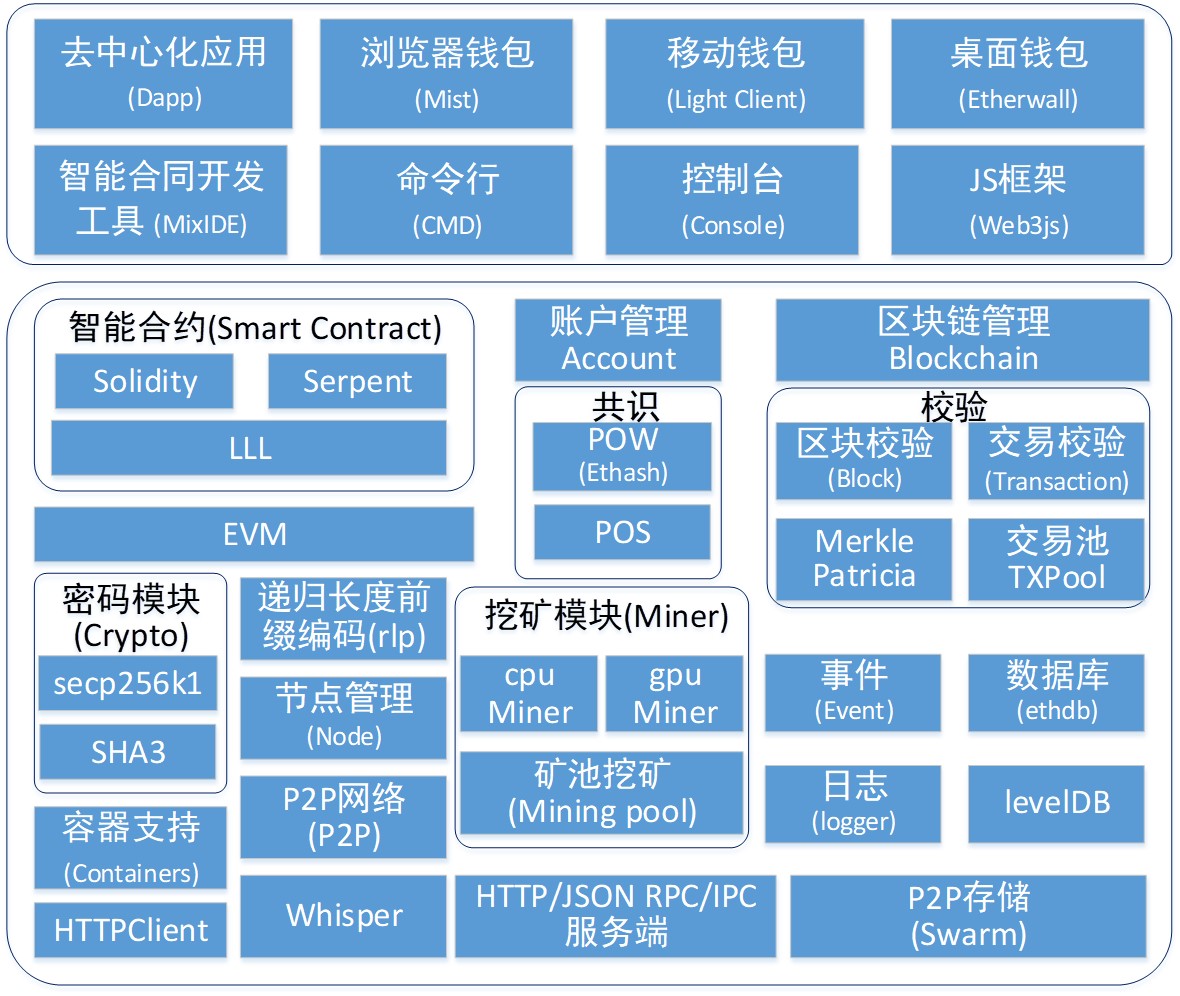
以太坊架构如上
| 比特币 | 以太坊 | |
|---|---|---|
| 账户设计 | 无账户的概念,每个账户的余额都是从他们在区块链上的UTXO计算出来的 | 拥有外部账户和合约账户,外部账户为用户账户,由私钥控制。合约账户是一种可编程账户,受代码控制并由外部账户激活 |
| 区块链设计 | 采用Merkle树将交易的哈希值组成二叉树状结构,顶层节点的哈希值用来校验交易清单 | 采用Merkle Patricia树来实现对交易和状态的校验和查询。 |
| 计算和图灵完备 | 非图灵完备 | 图灵完备 |
| EVM高级语言 | 不提供高级语言支持 | 提供Solidity、Serpent、LLL等高级语言让用户编写智能合约,高级语言会编译成在EVM中执行的EVM字节码 |
| P2P网络 | 比特币P2P协议 | 创建引入RLPx与Whisper网络协议,RLPx协议主要功能是在节点间建立通信并维持通信;Whisper协议主要用于Dapp之间的通信。以太坊P2P网络实现了更多功能扩展 |
| 事件 | 无事件概念 | 以太坊中的事件是一个以太坊日志和事件监测的协议的抽象。日志的记录中提供合约的地址;事件利用现有的ABI功能来解析日志记录 |
| 共识机制 | 采用PoW机制,依靠的是CPU计算难度问题 | 对比特币PoW机制进行改进,加入内存难度,具有抵抗单凭哈希运算优化的ASIC挖矿机的属性,以太坊未来将采用PoS共识机制 |
以太坊客户端
较为流行的是go-Ethereum和Parity
两种账户类型:外部持有账户(EOA)和合约账户(CA)
外部账号可以调用合约账户
以太坊中的世界状态定义为以太坊区块链中的全局状态,表示为以太坊地址和账户状态之间的映射。
u账户状态由4个字段组成:
-
nonce:当每次从地址发送交易时,该值递增。在合约账户中,该值代表账户创建的合约数量。
-
**balance:**账户余额。ether也认为是以太币的单位,另一个常用的单位是wei。
-
storageroot:代表Merkle Patricia树的根节点,并对账户的存储内容进行编码。(合约账户)
-
codehash:作为一个不可变字段,包含了与账户关联的智能合约代码的哈希值。在普通账户中,该字段包含一个空字符串的 Keccak 256位哈希值。另外,代码通过一个消息调用而被调用。
智能合约
定义:广义的智能合约是一种安全的、处于运行状态的计算机程序 ,体现了一种自动执行以及强制执行的协议。
狭义上讲,智能合约就是存储在区块链上的代码,用以实现执行特定的功能;能根据预先任意制定的规则来自动转移数字资产的系统。
智能合约有以下属性
- 自动执行
- 强制执行
- 明确的语义
- 安全性和不可阻止性
智能合约实际上是采用某种语言编写的、计算机或目标可理解的计算机程序.此外,智能合约还包含了以业务逻辑形式出现的各方之间的协议.另一个核心理念是,当某些条件满足时,智能契约将自动执行.另外,强制性意味着所有的合约条款都是按照规定和预期执行的,对于攻击者而言同样如此.
智能合约还具备安全性以及“不可阻挡”性,也就是说,计算机程序必须以这样一种方式设计:在合理的时间范围内具备容错能力并保持执行状态,即使外部因素处于不利状态下,相关程序也应能够执行和维护一个健康的内部状态.
智能合约应该具备确定性.据此,网络上的任何节点运行同一个智能合约,并获得相同的结果.如果最终结果在节点之间略有不同,那么将无法达成共识,因此,区块链上分布式共识的整个范例可能会失效.
-
智能合约的优点:
- 高效的实时更新
- 准确执行
- 较低的人为干预风险
- 去中心化权威
- 较低的运行成本
-
智能合约的缺点:
- 漏洞无法修复
- 隐私保护风险
- 缺乏有效监管
- 无法完全实施
智能合约The DAO事件:
DAO是最高的众筹项目之一,于2016年4月启动
DAO遭受攻击后,创建了硬分叉用于修复,但违背了去中心化的理念。
以太坊虚拟机
以太坊虚拟机时以太网上智能合约的运行环境
特点有①高度脚本化的设计语言使得智能合约的开发更简单;②和以太坊区块链一样同时存储于各个节点计算机上;③简单式堆栈架构,可应用于256位的Keccak散列算法和椭圆曲线计算;④可处理异常执行,包括堆栈溢出和无效指令等;⑤图灵完备,支持任何种类的计算,代码执行受参数Gas的严格制约。
智能合约的使用步骤
①编译合约===>>>②创建合约===>>>③部署合约===>>>④调用合约===>>>⑤监听合约||⑤销毁合约;
编译智能合约
以太坊上的合约就是一段可以被虚拟机执行的代码,这些代码以以太坊特有的二进制的形式存储在区块链上,并由以太坊虚拟机解释,因此被称为以太坊虚拟机位码。目前,用于以太坊智能合约开发的语言主要由Solidity、Serpent、LLL。
Solidity作为最流行的智能合约语言, 以其简单易用和高可读性受到以太坊设计者们的推荐
创建智能合约
创建合约,需要输入合约名称,合约版本号、合约创建者、合约的内容等
部署智能合约
部署合约就是将编译好的合约字节码通过外部账户发送交易的形式部署到以太坊区块链上,部署合约时,需要支付费用,要确保账户里有足够的余额(可以创建自己独立的测试网络,即自己的区块链,初始化的时候就可以初始化一些有余额的账户)。部署合约的一般流程:
①输入命令,部署合约;
②查看交易池待处理状况,如有待确认的交易,查看交易内容;
③查看挖矿日志,检验交易是否已发送到以太坊区块链上;
④等待矿工确认,利用txpool.status命令查看交易池状态;
⑤利用eth.getblock命令查看区块中是否含有关于合约的交易。
调用智能合约
智能合约的调用需要两个字段:和约地址(表明调用哪个合约)和合约abi(application binaryinterface)(表明具体用合约的哪个方法)
原因:首先,合约内容是可以完全重复的,所以我们根据合约名字、合约内容或者合约内容的哈希,去调用某一个合约都是可能重复的,只有合约地址是不会重复的。另外,合约内的函数名是可以重载的,就是说我们可以有多个叫setValue的函数,但是所需要的传入参数不同。EVM中使用了abi,便于调用,同时还能区分不同的函数。调用合约的一般流程:
①利用eth.contract来定义一个合约类,定义的合约类遵循ABI定义,构建合约实例
②调用合约
监听智能合约
合约部署后,可设置监听,既可以实时监控事件,也可以从历史区块中检索 event。
销毁智能合约
合约也可以结束,当一个合约通过kill方法将其杀死,那么我们将不能再和这个合约进行交互,如果一个合约被销毁,那么当前地址指向的是一个僵尸对象,这个僵尸对象调用任何方法都会抛出异常。此时需要调用selfdestruct(address)才能将其进行销毁。
需要指出的是只有拥有者才能销毁合约。
应用场景
数字身份
智能合约可以允许个人拥有并且控制包含数据、信誉和数字资产在内的数字身份。它允许个人自己决定向对手公开的数据内容,更为企业提供无缝了解客户的机会。
交易对手将不能获取敏感数据来验证交易。这减少了责任,同时促进了解你的客户法规(KYC)要求的无摩擦化,还提高了合规性,可恢复性和互操作性。
记录
智能合同可以将统一商业代码(Uniform Commercial Code,UCC)归档数字化,并且自动更新发布流程。他们还可以自动地完善贷款人的贷款担保物权。它们可以自动遵守在将来销毁所要求记录的规则。不仅如此,还能通过UCC留置权自动解锁,自动更新或自动请求抵押品。在执行此类功能时,智能合同能够降低法律成本。
证券
智能合约可以简化资本构成表的管理。它们还绕开证券托管链中的中间人,并促进自动支付股息,股票分拆和负债管理,同时降低操作风险。智能合约能将分布式账本上证券的工作流程数字化。
贸易金融
智能合约可以通过快速信用证和贸易支付开启来简化国际货物转移,同时获得更大的金融资产的流动性,提高买家,供应商和机构的融资效率。此外,政府必须确定在执行失败的情况下,特别是在纠纷和违约的情况下,法律应当如何界定责任。
对于贸易金融而言,结算系统、技术要求和离散生态系统的整合是重要的三元素。
供应链
智能合约可以让供应链中的每一步变得实时可见。互联网设备可以将产品从工厂车间转移到商店货架之间的每个步骤都记录下来。它们促进粒度级别的库存跟踪,这有利于保护供应链的融资、保险和风险。这种增强的跟踪和验证技术降低了盗窃和欺诈的风险。如果想让智能合约实现大规模应用,供应链参与者必须证明其身份,包括公司,机构,个人,传感器,设施和产品等。
汽车保险
智能合约可以改善目前混乱的汽车投保及赔付流程。智能合约可以记录相关政策、驾驶记录和驾驶员报告,允许互联网车辆在发生事故后立即执行索赔。合约能够自动处理索赔,验证和付款过程。每个投保人的存储库中都包括了驾驶记录,车辆和事故报告历史。消除重复的报告也会节省成本。不过,这些都需要跨行业协作来解决技术,监管和财务上的挑战。
P2P
p2p简介
定义:
网络的参与者共享他们所拥有的一部分硬件资源(处理能力、存储能力、网络连接能力、打印机等),这些共享资源通过网络提供服务和内容,能被其它对等节点(Peer)直接访问而无需经过中间实体。在此网络中的参与者既是资源(服务和内容)提供者(Server),又是资源获取者(Client)。
P2P网络原理
从计算模式上来说,P2P打破了传统的Client/Server (C/S)模式,在网络中的每个结点的地位都是对等的。每个结点既充当服务器,为其他结点提供服务,同时也享用其他结点提供的服务。
P2P改变了目前互联网中占主导地位的客户/服务器结构中信息在消费者和生产者之间的不平衡。由于P2P网络没有中心节点(中心服务器),网络中的每个节点具有信息消费者和信息提供者的双重身份P2P,同时具有信息通信方面的功能,因此P2P应用的实现扩展性强,实现方式灵活多样,部署成本低,给互联网的发布和共享带来了巨大的空间。
P2P特点
-
P2P是动态的:动态地提供信息和服务
-
P2P是双向的:切实实现信息和服务的交换与共享
-
P2P是直接的:无中介、等级和格式限制,直接交换信息和服务
-
P2P是平等的:生产者与消费者地位平等,角色合二为一
-
P2P是及时的:无服务器参与空间分配,可提供实时、可升级的信息
-
P2P是有效的:可充分利用个人计算机的硬件设备、传输信息和服务时目标确定
P2P优势
-
非中心化
网络中的资源和服务分散在所有节点上,信息传输和服务的实现都直接在节点之间进行,可以无需中间环节和服务器的介入,避免了可能的瓶颈。
-
可扩展性
在P2P网络中,节点在获取其他节点资源的同时也为其他节点服务。随着用户的加入,不仅服务的需求增加了,系统整体的资源和服务能力也在同步扩充,始终能较便捷地满足用户的需求。
-
健壮性
P2P网络通常都是以自组织的方式建立起来的,并允许节点自由地加入和离开。由于服务是分散在各个节点之间进行的,当部分节点或网络遭到破坏时,对其他部分的影响很小。
-
高性价比
采用P2P架构可以有效地利用互联网中散步的大量普通节点,将计算任务或存储资料分布到所有节点上,利用其中空置的计算能力或存储空间达到高性能计算和海量存储的目的。
-
隐私保护
在P2P中,所有参与者可以提供中继转发的功能,因此大大提高了匿名通信的灵活性和可靠性,能够为用户提供更好的隐私保护。
-
负载均衡
在P2P网络环境下由于每个节点既是服务器又是客户端,减少了对传统C/S结构中服务器计算能力、存储能力的要求,同时由于资源分布在多个节点,因此能更好地实现整个网络的负载均衡。
P2P加密
-
文件内容共享和下载,例如Napster、Gnutella、eDonkey等
-
计算能力和存储共享,例如SETI@home、Avaki等
-
基于P2P技术的协同与服务共享平台,例如JXTA等
-
即时通讯工具,包括ICQ、QQ、Yahoo Messenger等
-
P2P通讯与信息共享,例如Skype、Crowds、Onion Routing等;
-
基于P2P技术的网络电视:沸点、PPStream、 PPLive、 QQLive、 SopCast等。
拓扑结构
拓扑结构是指分布式系统中各个计算单元之间的物理或逻辑的互联关系,结点之间的拓扑结构一直是确定系统类型的重要依据。
P2P网络的拓扑结构
根据结构关系可以将P2P系统细分为四种拓扑形式:
-
中心化拓扑(Centralized Topology)
-
全分布式非结构化拓扑(Decentralized Unstructured Topology)
-
全分布式结构化拓扑(Decentralized Structured Topology,也称作DHT网络)
-
半分布式拓扑(Partially Decentralized Topology)
中心化拓扑结构
即存在一个中心节点保存了其他所有节点的索引信息,索引信息一般包括IP地址、端口、节点资源等。
Napster是最早出现的P2P系统之一,它的工作原理如图所示。当某个用户需要某个音乐文件时,首先连接到Napster中央索引服务器,在服务器上进行检索,服务器返回存有该文件的用户信息,再由请求者直接连到文件的所有者传输文件。Napster首先实现了文件查询与文件传输的分离,有效地节省了中央服务器的带宽消耗,减少了系统的文件传输延时。
-
优点
- 维护简单、资源发现效率高
-
缺点
- 中央索引服务器的瘫痪容易导致整个网络的崩溃,因此可靠性和安全性较低。
- 随着网络规模的扩大,对中央索引服务器进行维护和更新的费用将急剧增加,所需成本较高。
- 中央索引服务器的存在常引起版权问题上的纠纷,服务提供商容易被追究法律责任。